Guanmin Liu's CV
EDUCATION
- Ph.D. in Shanghai, Fudan University, 2024-2028
- M.S. in Shanghai, Tongji University (recommended for admission), 2021-2024
- B.S. in Nanjing, Hohai University, 2017-2021
WORK EXPERIENCE
- September 2022 - September 2023: Research Intern
- Ele.me, Alibaba Group
- Study on multi-modal image generation and image editing
- September 2024 – Present: Ph.D. Student
- Collaborative Information and Systems Laboratory, Fudan University
- September 2021 – May 2024: Postgraduate Student
- Intelligence Information Processing Laboratory, Tongji University
- Study on generated image evaluation, image-based 3D neural rendering representation and amodal segmentation
- May 2018 – June 2021: Undergraduate Student
- Robotics Motion and Vision Laboratory, Hohai University
- Study on Visual SLAM
TECHNICAL SKILLS & OTHERS
- Programming Languages
- Python, C++, Java, JavaScript, MATLAB, Latex, SQL
- Frameworks and Platforms
- Git, PyTorch, Linux, Flask, Unity 3D
- Hobbies
- Martial Arts, Travelling, Creative Media Production
PUBLICATIONS
Author: **Guanming Liu**, Zhihua Wei, et al
Abstract: Implicit neural representations (INRs) have demonstrated their effectiveness in continuous modeling for image signals. However, INRs typically operate in a continuous space, which makes it difficult to integrate the discrete symbols and structures inherent in human language. Despite this, text features carry rich semantic information that is helpful for visual representations, alleviating the demand of INR-based generative models for improvement in diverse datasets. To this end, we propose EIDGAN, an Efficient scale-Invariant Dual-modulated generative adversarial network, extending INRs for text-to-image generation while balancing network's representation power and computation costs. The spectral modulation utilizes Fourier transform to introduce global sentence information into the channel-wise frequency domain of image features. The cross attention modulation, as second-order polynomials incorporating the style codes, introduces local word information while recursively increasing the expressivity of a synthesis network. Benefiting from the column-row entangled bi-line design, EIDGAN enables text-guided generation of any-scale images and semantic extrapolation beyond image boundaries. We conduct experiments on text-to-image tasks based on MS-COCO and CUB datasets, demonstrating competitive performance on INR-based methods.
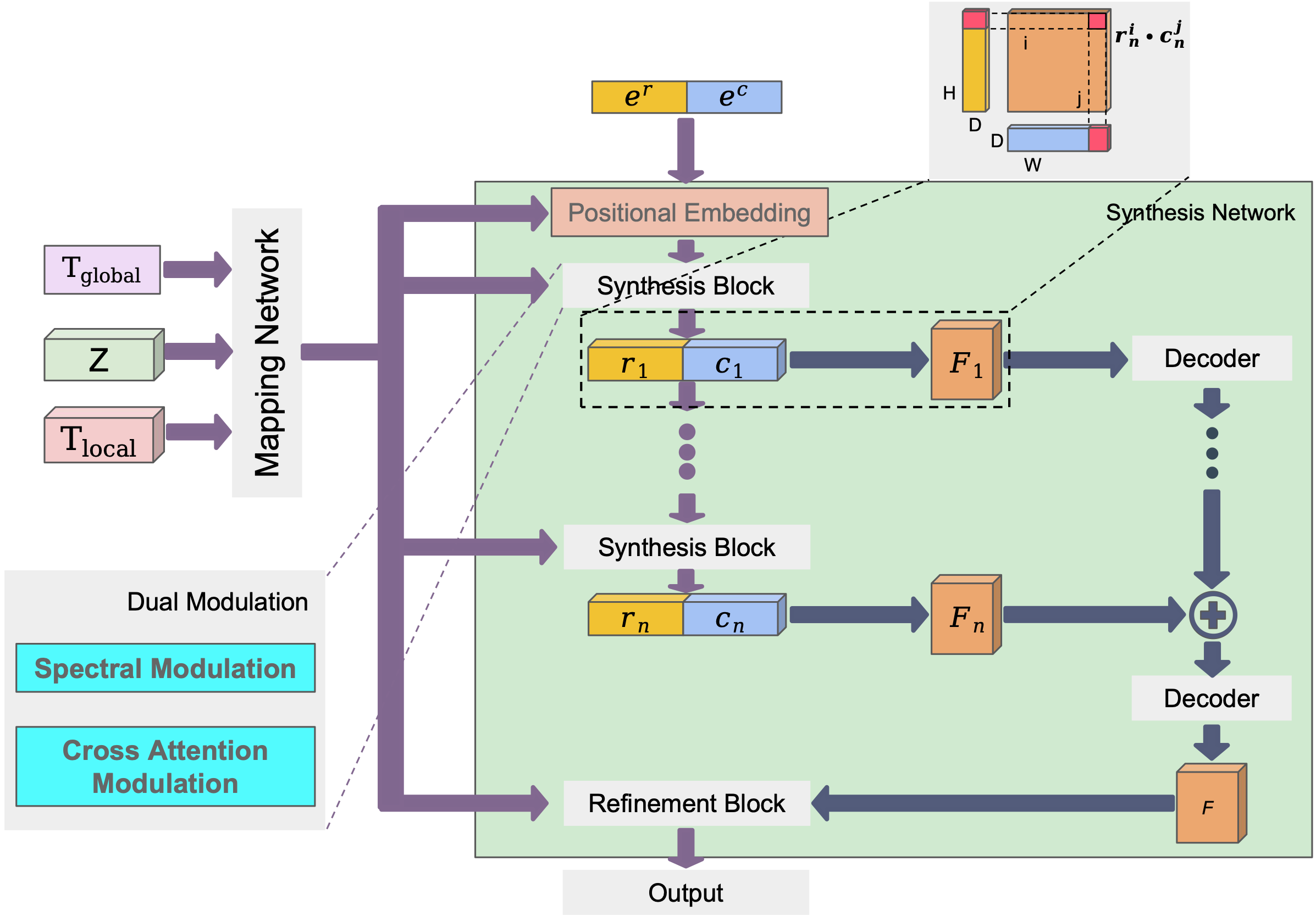
Author: Heng Zhang, Zhihua Wei, **Guanming Liu**, et al
Abstract: External knowledge representations play an essential role in knowledge-based visual question and answering to better understand complex scenarios in the open world. Recent entity-relationship embedding approaches are deficient in some of representing complex relations, resulting in a lack of topic-related knowledge but the redundancy of topic-irrelevant information. To this end, we propose MKEAH to represent Multimodal Knowledge Extraction and Accumulation on Hyperplanes. To ensure that the length of the feature vectors projected to the hyperplane compares equally and to filter out enough topic-irrelevant information, two losses are proposed to learn the triplet representations from the complementary views: range loss and orthogonal loss. In order to interpret the capability of extracting topic-related knowledge, we present Topic Similarity (TS) between topic and entity-relation. Experimental results demonstrate the effectiveness of hyperplane embedding for knowledge representation in knowledge-based visual question answering. Our model outperforms the state-of-the-art methods by 2.12% and 3.24%, respectively, on two challenging knowledge-required datasets: OK-VQA and KRVQA. The obvious advantages of our model on TS shows that using hyperplane embedding to represent multimodal knowledge can improve the ability of the model to extract topic-related knowledge.

Author: Ping Zhao, Panyue Chen, **Guanming Liu**
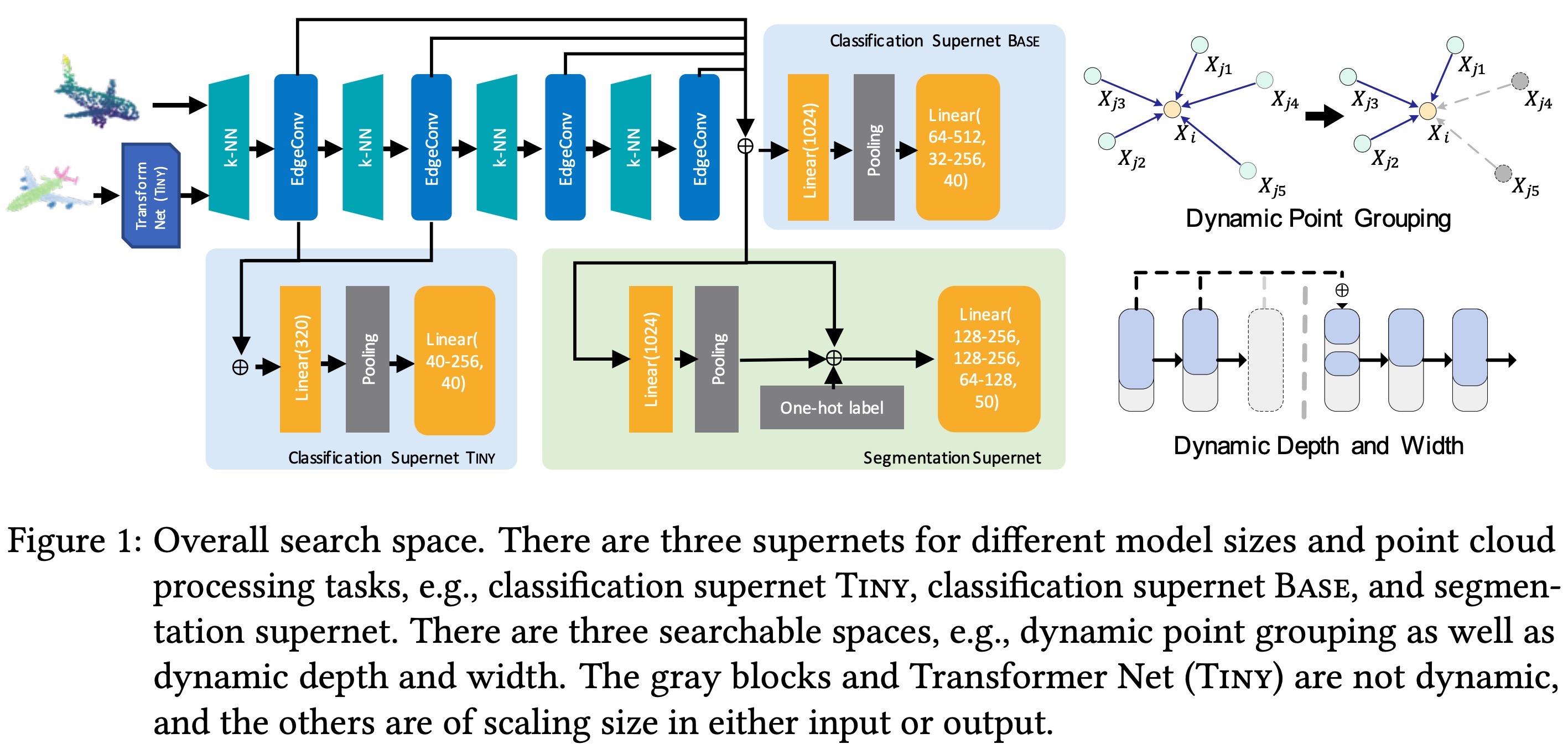
Abstract: Deep neural networks for 3D point cloud processing have exhibited superior performance on many tasks. However, the structure and computational complexity of existing networks are relatively fixed, which makes it difficult for them to be flexibly applied to devices with different computational constraints. Instead of manually designing the network structure for each specific device, in this paper, we propose a novel training-free neural architecture search algorithm which can quickly sample network structures that satisfy the computational constraints of various devices. Specifically, we design a cell-based search space that contains a large number of latent network structures. The computational complexity of these structures varies within a wide range to meet the needs of different devices. We also propose a multi-objective evolutionary search algorithm. This algorithm scores the candidate network structures in the search space based on multiple training-free proxies, encourages high-scoring networks to evolve, and gradually eliminates low-scoring networks, so as to search for the optimal network structure. Because the calculation of training-free proxies is very efficient, the whole algorithm can be completed in a short time. Experiments on 3D point cloud classification and part segmentation demonstrate the effectiveness of our method
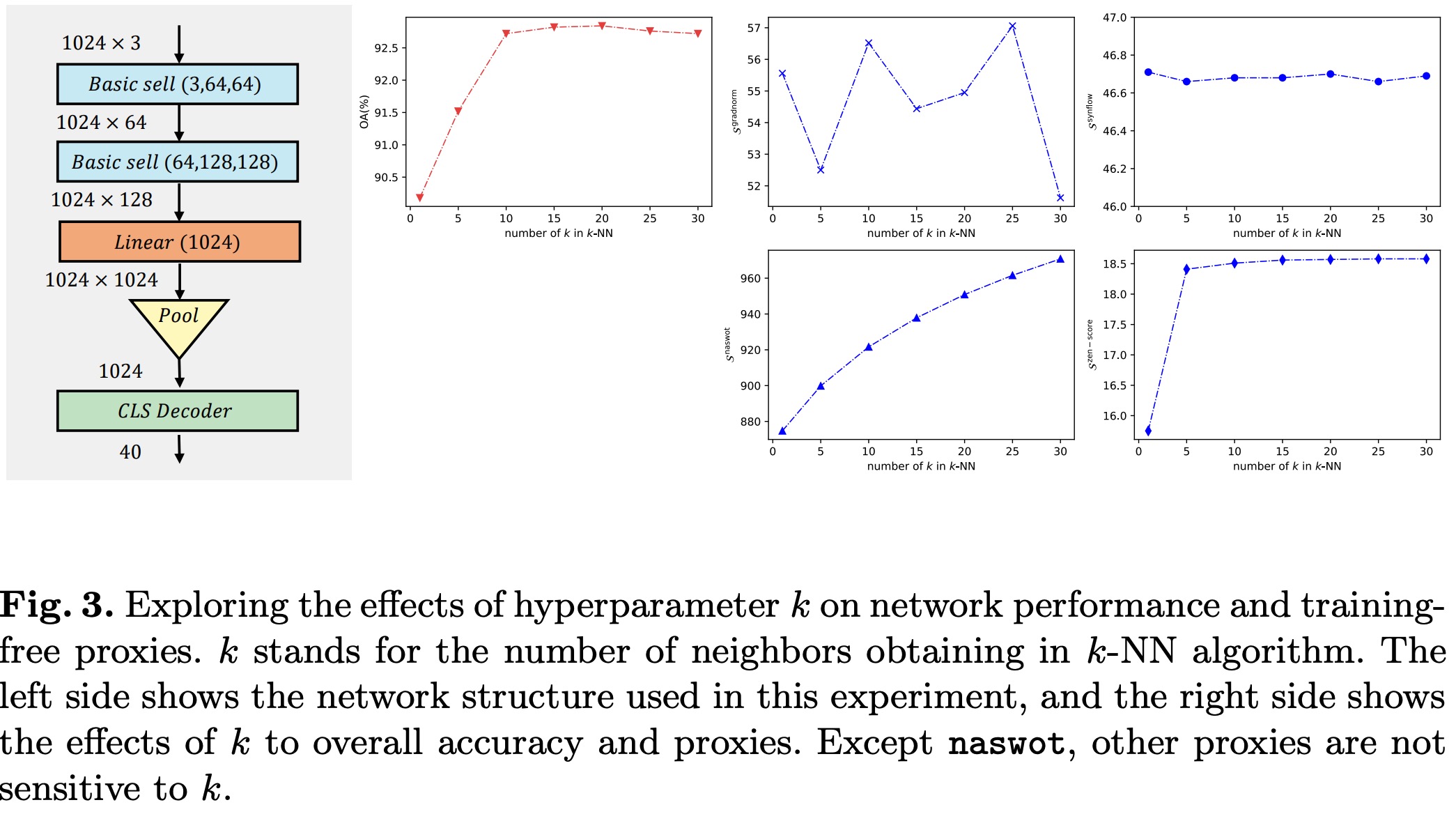
Author: Panyue Chen, Rui Wang, Ping Zhao, **Guanming Liu**, et al.
Abstract: Despite superior performance on various point cloud processing tasks, convolutional neural networks (CNN) are challenged by deploying on resource-constraint devices such as cars and cellphones. Most existing convolution variants, such as dynamic graph CNN (DGCNN), require elaborately manual design and scaling-up across various constraints to accommodate multiple hardware deployments. It results in a massive amount of computation and limits the further application of these models. To this end, we propose a one-shot neural architecture search method for point cloud processing to achieve efficient inference and storage across various constraints.We conduct our method with DGCNN to create a compressed model.Extensive experiments on the point cloud classification and part segmentation tasks strongly evidence the benefits of the proposed method. Compared with the original network, we achieve 17.5$ imes$ computation saving on the classification task with the comparable performance and obtain a 2.7$ imes$ model compression ratio on the part segmentation task with slight IoU loss.