
Extending Implicit Neural Representations for Text-to-Image Generation
**Guanming Liu**, Zhihua Wei, et al
Published in ICASSP, 2024
Abstract
Implicit neural representations (INRs) have demonstrated their effectiveness in continuous modeling for image signals. However, INRs typically operate in a continuous space, which makes it difficult to integrate the discrete symbols and structures inherent in human language. Despite this, text features carry rich semantic information that is helpful for visual representations, alleviating the demand of INR-based generative models for improvement in diverse datasets. To this end, we propose EIDGAN, an Efficient scale-Invariant Dual-modulated generative adversarial network, extending INRs for text-to-image generation while balancing network’s representation power and computation costs. The spectral modulation utilizes Fourier transform to introduce global sentence information into the channel-wise frequency domain of image features. The cross attention modulation, as second-order polynomials incorporating the style codes, introduces local word information while recursively increasing the expressivity of a synthesis network. Benefiting from the column-row entangled bi-line design, EIDGAN enables text-guided generation of any-scale images and semantic extrapolation beyond image boundaries. We conduct experiments on text-to-image tasks based on MS-COCO and CUB datasets, demonstrating competitive performance on INR-based methods.
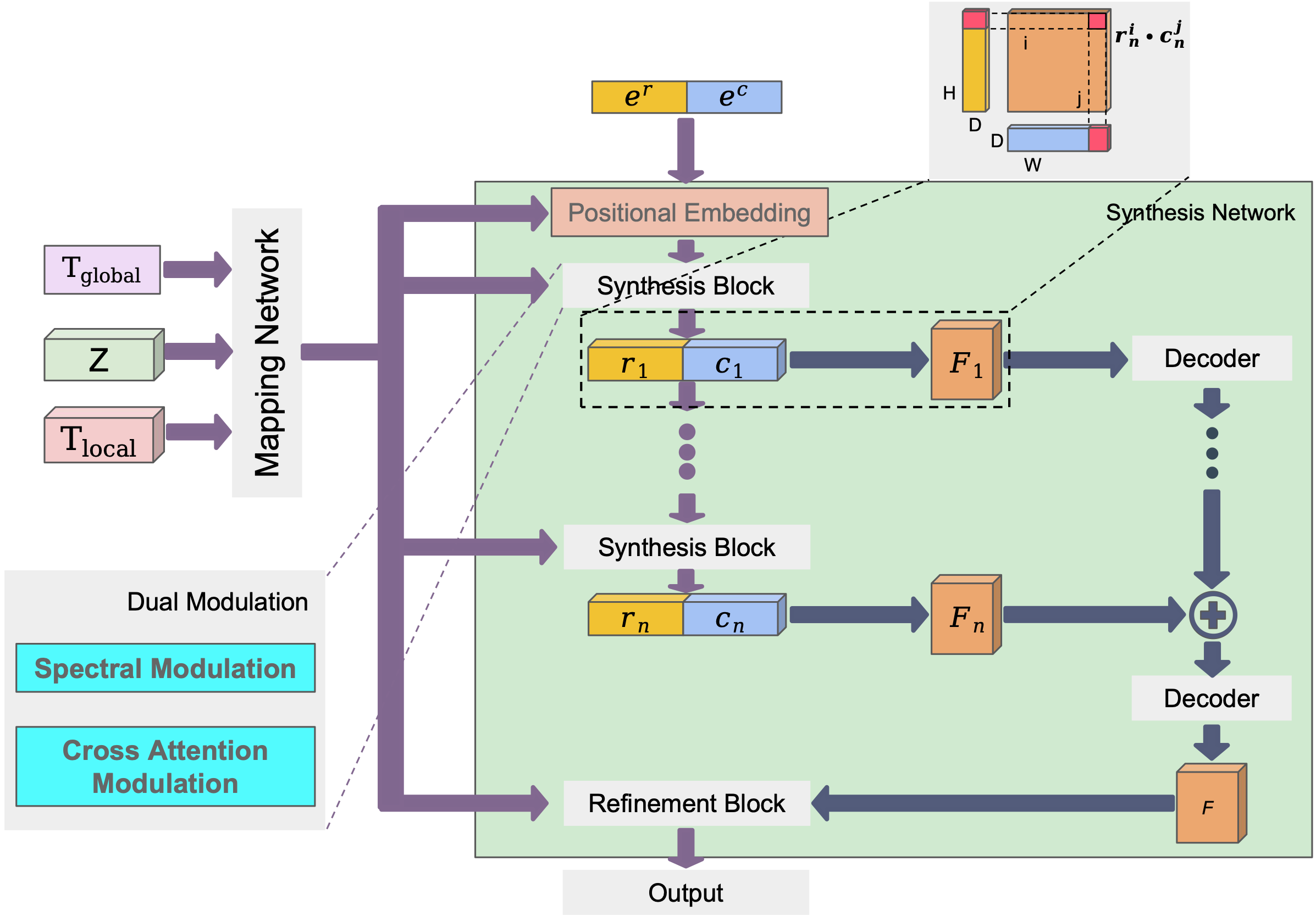
EIDGAN architecture overview.
The mapping network incorporates global and local text features with latent codes. The synthesis network, which employs a thick bi-line representation to improve memory-efficiency, incorporates proposed dual modulation mechanism, which effectively regulates the pixel features of semantics and frequency components.
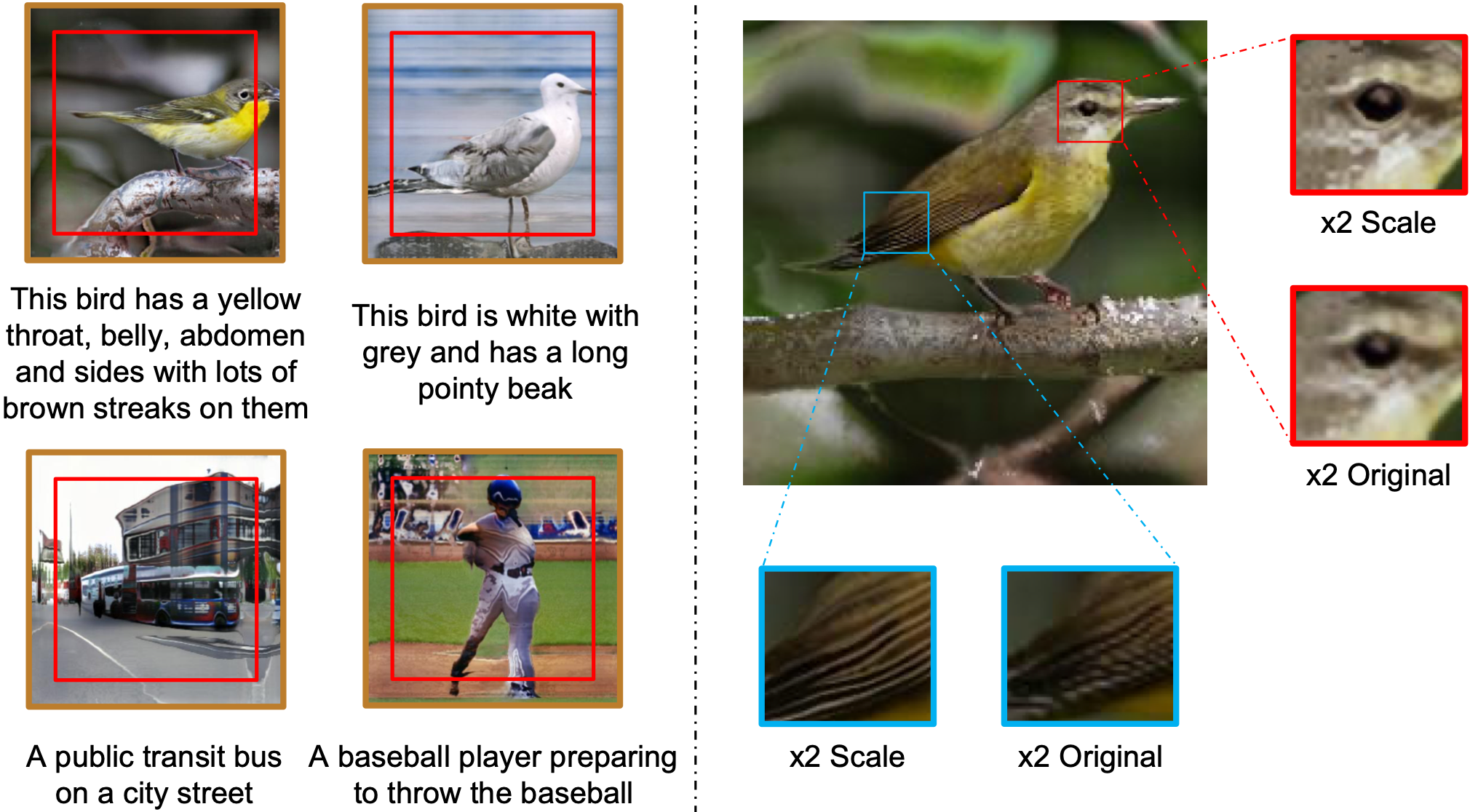
Beyond-boundary extrapolation and Scale-consistent interpolation outputs. We only train models at a 256 × 256 setting.